上一篇文章
【文件上传系列】No.1 大文件分片、进度图展示(原生前端 + Node 后端 & Koa)
秒传效果展示
秒传思路
整理的思路是:根据文件的二进制内容生成 Hash 值,然后去服务器里找,如果找到了,说明已经上传过了,所以又叫做秒传(笑)
整理文件夹、path.resolve() 介绍
接着上一章的内容,因为前端和后端的服务都写在一起了,显得有点凌乱,所以我打算分类一下
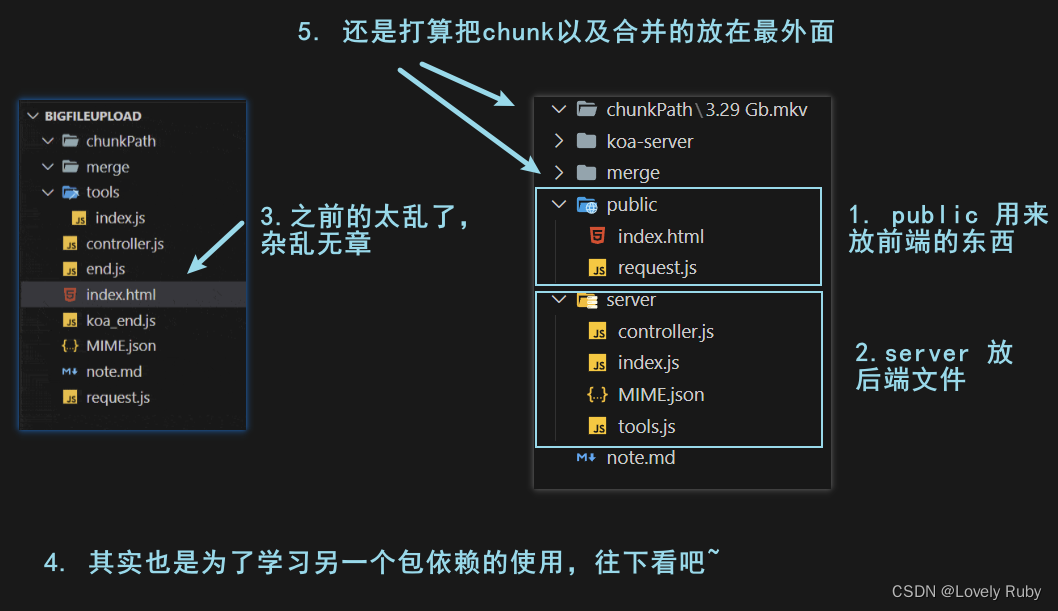
改了文件路径的话,那么各种引用也要修改,引用就很好改了,这里就不多说了
这里讲一下 path 的修改,为了方便修改 path,引用了 path 依赖,使用 path.resolve() 方法就很舒服的修改路径,常见的拼接方法如下图测试:(如果不用这个包依赖的话,想一下如何返回上一个路径呢?可能使用 split('/)[1] 类似这种方法吧。)
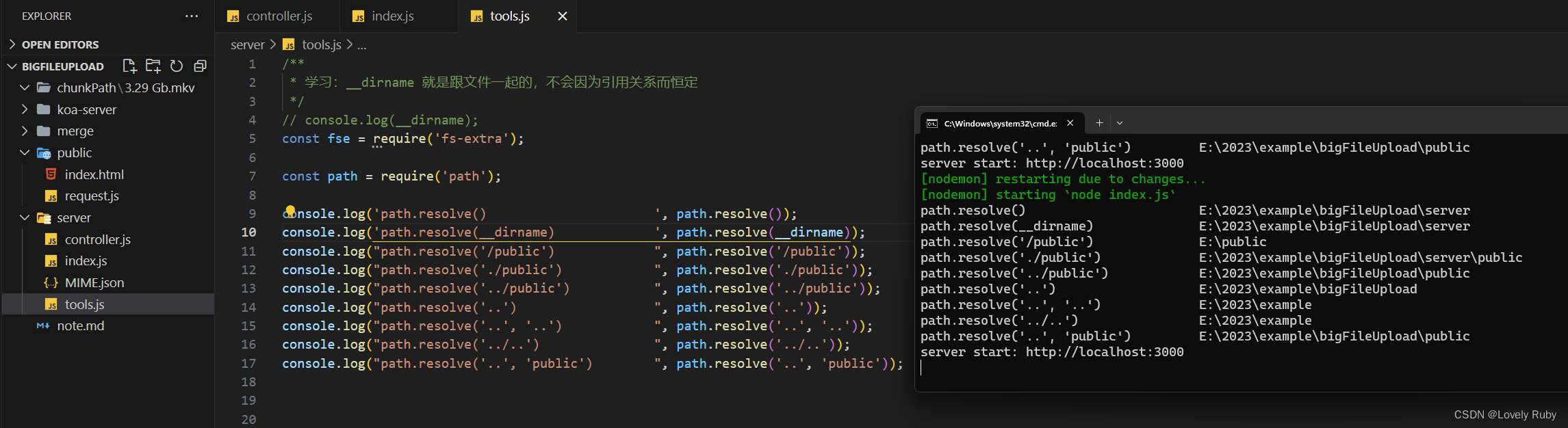
会使用这个包依赖之后就可以修改服务里的代码了:

200 页面正常!资源也都加载了!

前端
思路
具体思路如下
- 计算文件整体
hash ,因为不同的文件,名字可能相同,不具有唯一性,所以根据文件内容计算出来的 hash 值比较靠谱,并且为下面秒传做准备。
- 利用 web-worker 线程:因为如果是很大的文件,那么分块的数量也会很多,读取文件计算
hash 是非常耗时消耗性能的,这样会使页面阻塞卡顿,体验不好,解决的一个方法是,我们开一个新线程来计算 hash
工作者线程简介
《高级JavaScript程序设计》27 章简介: 
工作者线程的数据传输如下:
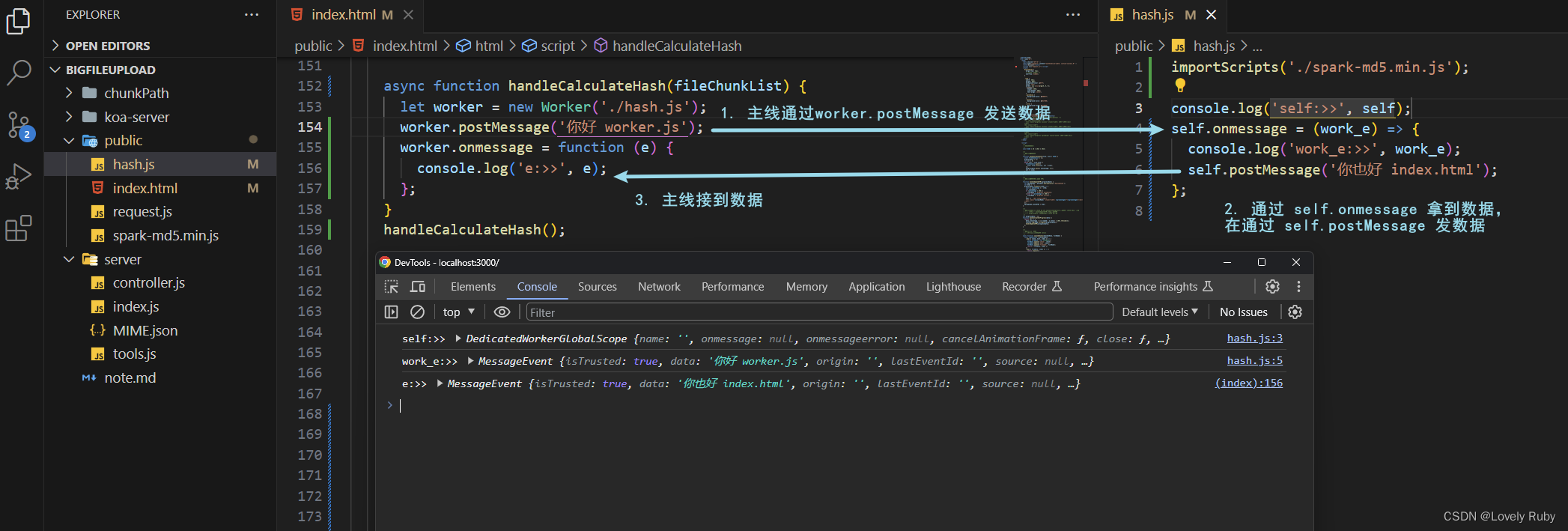
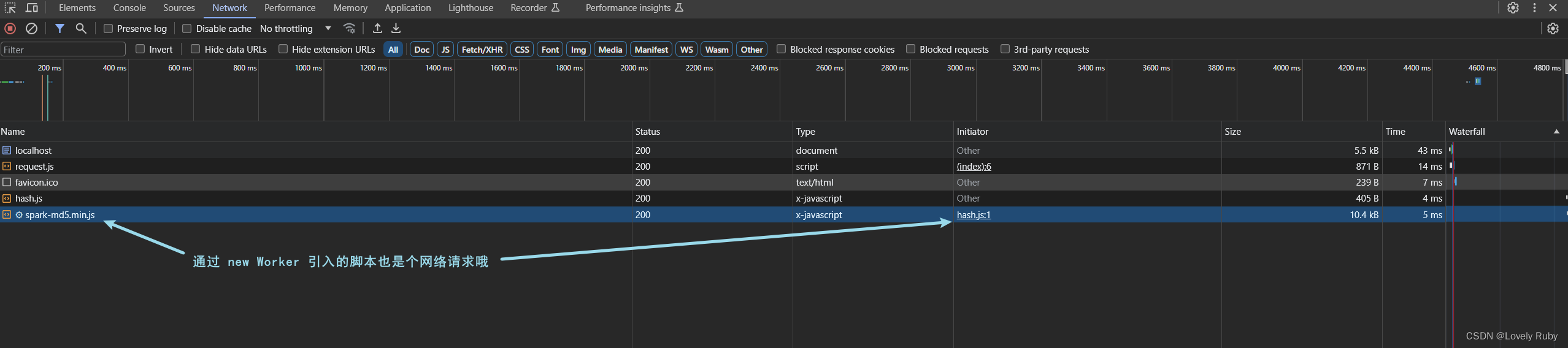
注意在 worker 中引入的脚本也是个请求!
1
2
3
4
5
6
7
8
9
|
function handleCalculateHash(fileChunkList) {
let worker = new Worker('./hash.js');
worker.postMessage('你好 worker.js');
worker.onmessage = function (e) {
console.log('e:>>', e);
};
}
handleCalculateHash();
|
1
2
3
4
5
|
self.onmessage = (work_e) => {
console.log('work_e:>>', work_e);
self.postMessage('你也好 index.html');
};
|
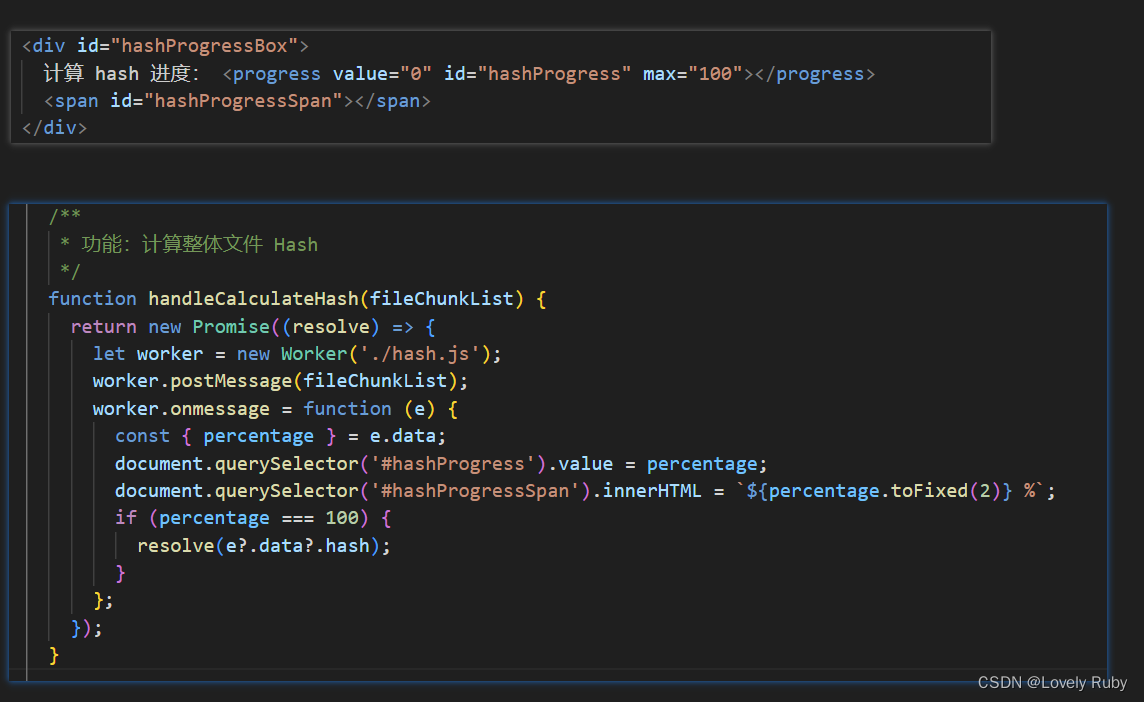
计算整体文件 Hash
前端拿到 Blob,然后通过 fileReader 转化成 ArrayBuffer,然后用 append() 方法灌入 SparkMD5.ArrayBuffer() 实例中,最后 SparkMD5.ArrayBuffer().end() 拿到 hash 结果

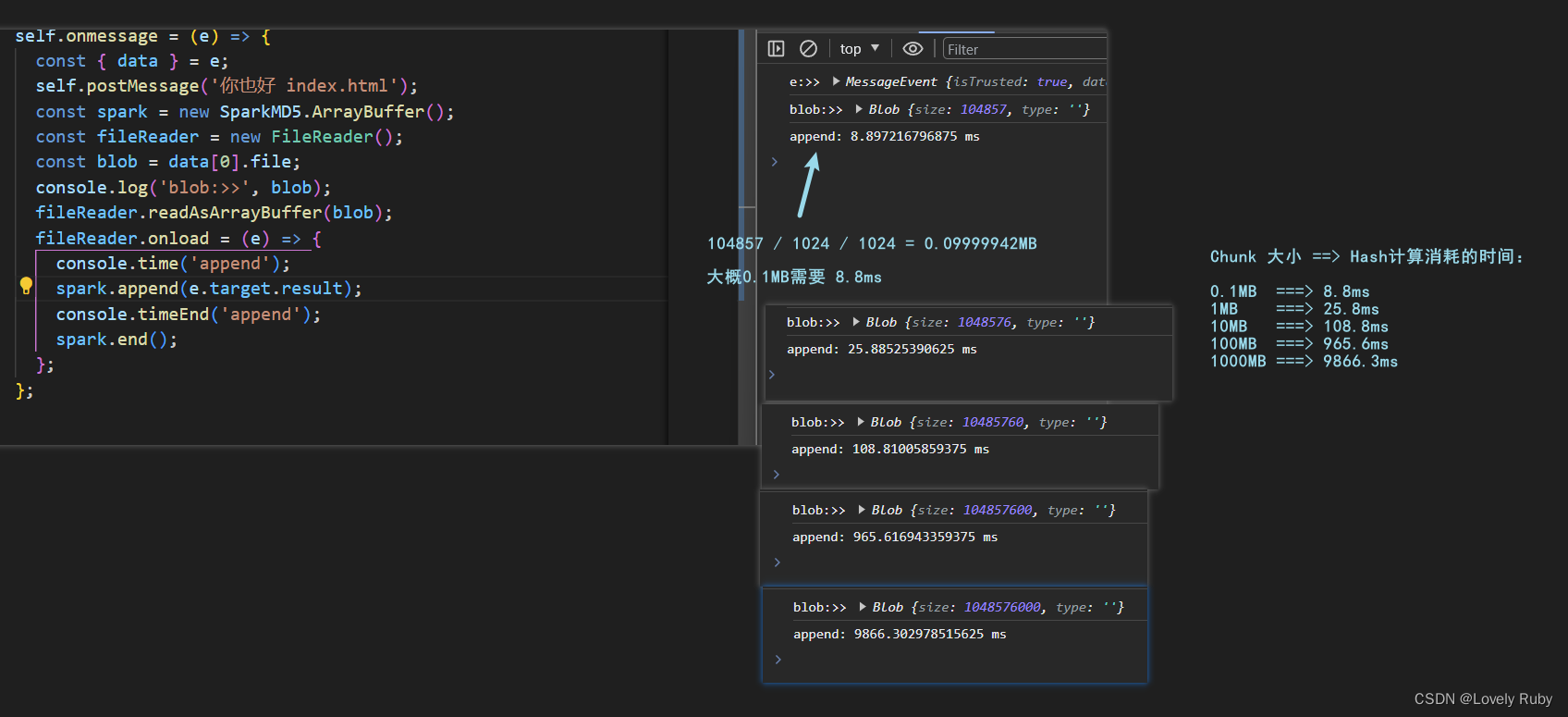
SparkMD5 计算 Hash 性能简单测试
js-spark-md5 的 github 地址
配置 x99 2643v3 六核十二线程 基础速度:3.4GHz,睿频 3.6GHz,只测试了一遍。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
self.onmessage = (e) => {
const { data } = e;
self.postMessage('你也好 index.html');
const spark = new SparkMD5.ArrayBuffer();
const fileReader = new FileReader();
const blob = data[0].file;
fileReader.readAsArrayBuffer(blob);
fileReader.onload = (e) => {
console.time('append');
spark.append(e.target.result);
console.timeEnd('append');
spark.end();
};
};
|
工作者线程:计算 Hash
这里有个注意点,就是我们一定要等到 fileReader.onload 读完一个 chunk 之后再去 append 下一个块,一定要注意这个顺序,我之前想当然写了个如下的错误版本,就是因为回调函数 onload 还没被调用(文件没有读完),我这里只是定义了回调函数要干什么,但没有保证顺序是一块一块读的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
const chunkLength = data.length;
let curr = 0;
while (curr < chunkLength) {
const blob = data[curr].file;
curr++;
const fileReader = new FileReader();
fileReader.readAsArrayBuffer(blob);
fileReader.onload = (e) => {
spark.append(e.target.result);
};
}
const hash = spark.end();
console.log(hash);
|
如果想保证在回调函数内处理问题,我目前能想到的办法:一种方法是递归,另一种方法是配合 await
这个是非递归版本的,比较好理解。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
async function handleBlob2ArrayBuffer(blob) {
return new Promise((resolve) => {
const fileReader = new FileReader();
fileReader.readAsArrayBuffer(blob);
fileReader.onload = function (e) {
resolve(e.target.result);
};
});
}
self.onmessage = async (e) => {
const { data } = e;
self.postMessage('你也好 index.html');
const spark = new SparkMD5.ArrayBuffer();
for (let i = 0, len = data.length; i < len; i++) {
const eachArrayBuffer = await handleBlob2ArrayBuffer(data[i].file);
spark.append(eachArrayBuffer);
}
const hash = spark.end();
};
|
递归的版本代码比较简洁
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
self.onmessage = (e) => {
const { data } = e;
console.log(data);
self.postMessage('你也好 index.html');
const spark = new SparkMD5.ArrayBuffer();
function loadNext(curr) {
const fileReader = new FileReader();
fileReader.readAsArrayBuffer(data[curr].file);
fileReader.onload = function (e) {
const arrayBuffer = e.target.result;
spark.append(arrayBuffer);
curr++;
if (curr < data.length) {
loadNext(curr);
} else {
const hash = spark.end();
console.log(hash);
return hash;
}
};
}
loadNext(0);
};
|
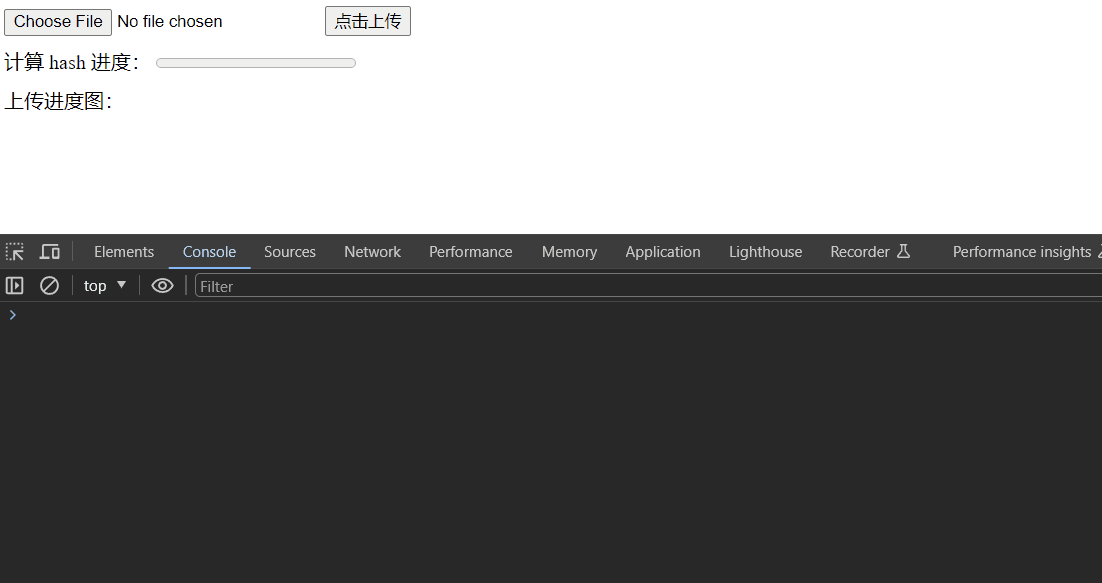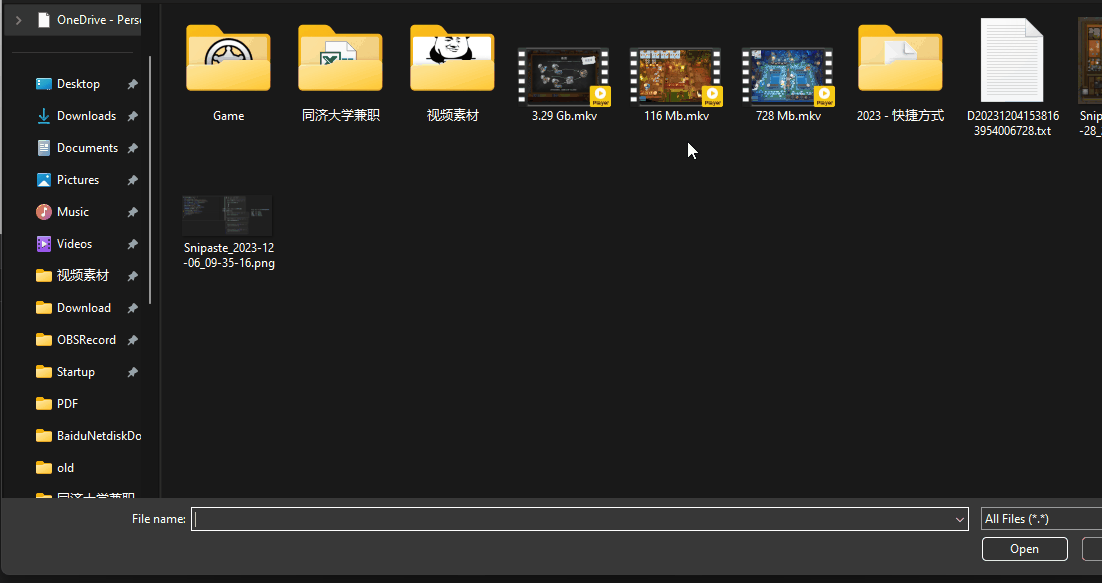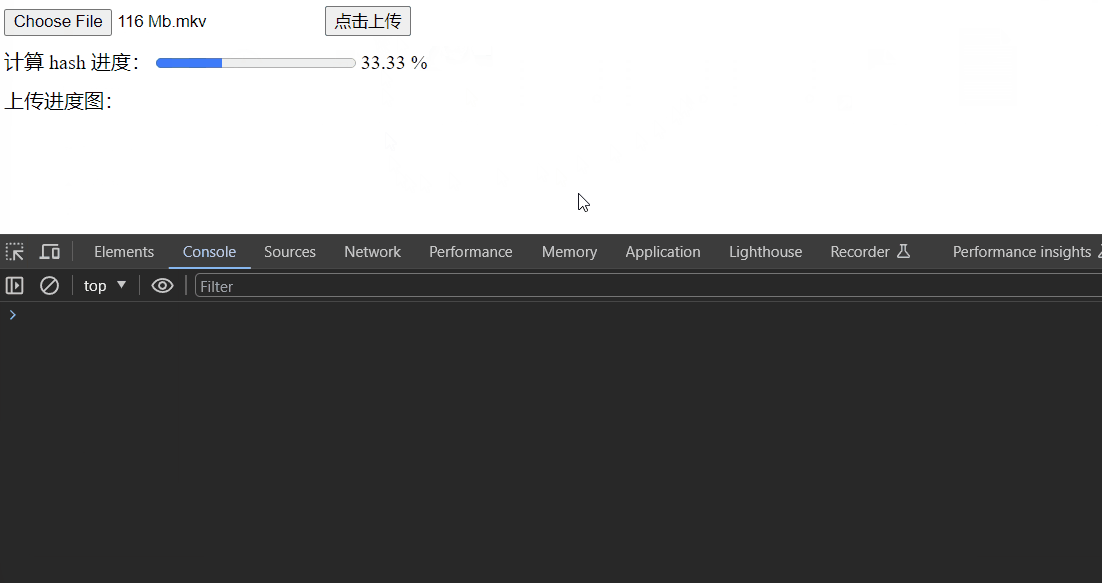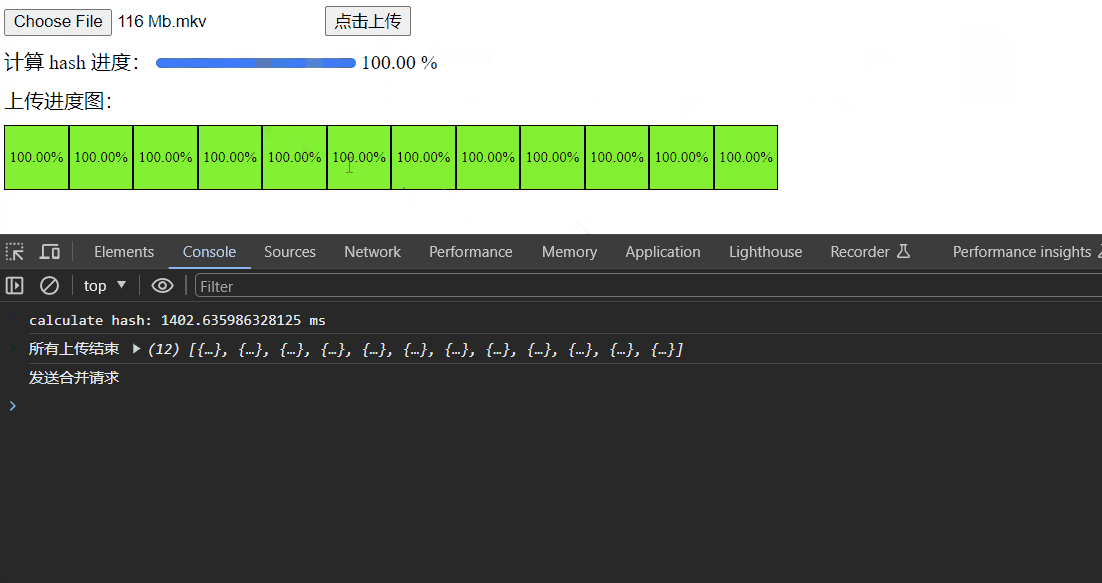
我们在加上计算 hash 进度的变量 percentage就差不多啦
官方建议用小切块计算体积较大的文件,点我跳转官方包说明

ok 这个工作者线程的整体代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| importScripts('./spark-md5.min.js');
async function handleBlob2ArrayBuffer(blob) {
return new Promise((resolve) => {
const fileReader = new FileReader();
fileReader.readAsArrayBuffer(blob);
fileReader.onload = function (e) {
resolve(e.target.result);
};
});
}
self.onmessage = async (e) => {
const { data } = e;
const spark = new SparkMD5.ArrayBuffer();
let percentage = 0;
for (let i = 0, len = data.length; i < len; i++) {
const eachArrayBuffer = await handleBlob2ArrayBuffer(data[i].file);
percentage += 100 / len;
self.postMessage({
percentage,
});
spark.append(eachArrayBuffer);
}
const hash = spark.end();
self.postMessage({
percentage: 100,
hash,
});
self.close();
};
|
主线程调用 Hash 工作者线程
把处理 hash 的函数包裹成 Promise,前端处理完 hash 之后传递给后端
把每个chunk 的包裹也精简了一下,只传递 Blob和 index

再把后端的参数调整一下
最后我的文件结构如下:
添加 hash 进度
简单写一下页面,效果如下:
后端
接口:判断秒传
写一个接口判断一下是否存在即可
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
async handleVerify(req, res, MERGE_DIR) {
const postData = await handlePostData(req);
const { fileHash, fileName } = postData;
const ext = path.extname(fileName);
const willCheckMergedName = `${fileHash}${ext}`;
const willCheckPath = path.resolve(MERGE_DIR, willCheckMergedName);
if (fse.existsSync(willCheckPath)) {
res.end(
JSON.stringify({
code: 0,
message: 'existed',
})
);
} else {
res.end(
JSON.stringify({
code: 1,
message: 'no exist',
})
);
}
}
|
前端这边在 hash 计算后把结果传给后端,让后端去验证
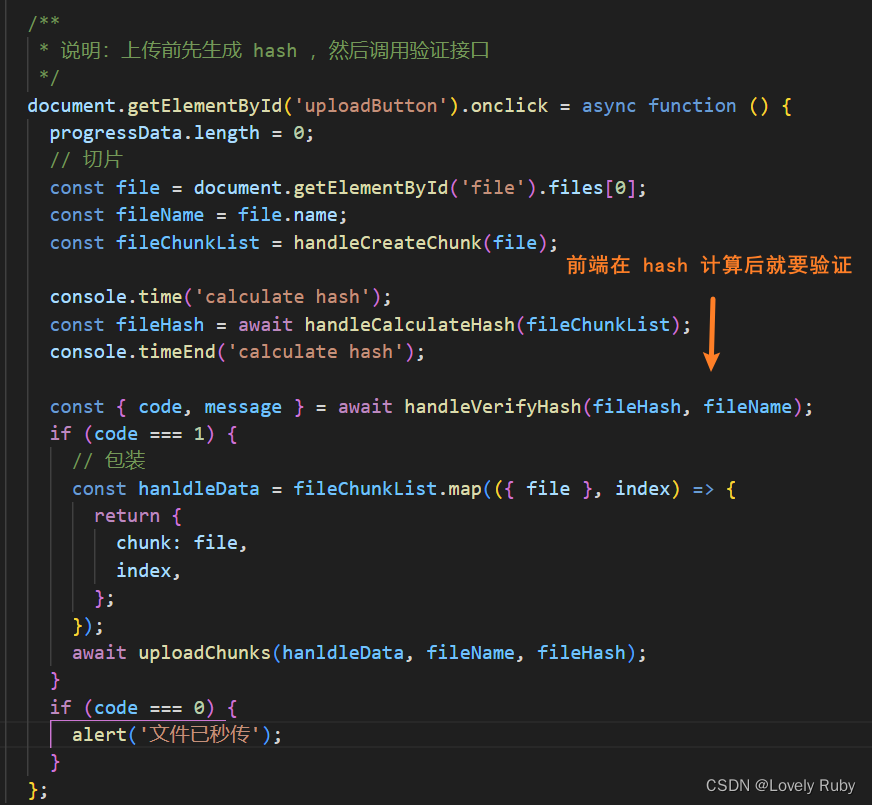
秒传就差不多啦!
参考文章
path.resolve() 解析- 字节跳动面试官:请你实现一个大文件上传和断点续传
- 《高级JavaScript设计》第四版:第 27 章
- Spark-MD5
- 布隆过滤器







