Node.js 起步 什么是 Node?
灵魂一问:什么是 NodeNode 是 基于 V8 引擎的 JavaScript 运行时。
说白了,就是用来跑 JavaScript 语言的一个环境,当然,前期可以这样去理解。
个人理解:有兴趣的话可以去深入学学 AST 抽象语法树 还有 V8 引擎的一些基本原理,引擎是如何解析 JavaScript 这门语言的?不管是什么语言,都是一堆字符串组成的,通过不同的引擎去解释关键字,变量之类的,从而运行相应的功能。
这些功能不知道也不要紧,不影响我们继续学习。先学吃饭在学养家!基础还是要打好的,没错说的就是我。
安装 Node.js 官网
windows 注意:配置环境变量,网上查一下,很多的,这里就不在赘述了。可以参考知乎:Node 环境变量
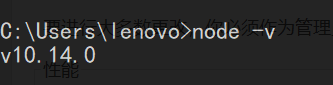
查看是否安装好 node:终端运行 node -v,如果出现版本号,说明安装成功了。否则的话,重新在安装一遍吧
常见概念解释
Q:普通 js 和 node.js 有啥区别? js 在哪里执行了,如果在 node 里执行了,那么你可以叫这个 js 为 nodejs
Q:什么是客户端,什么是服务端?
上手:用 Node 启动简单的服务 首先建一个 .js 文件,不要以 node 为文件名。然后把下面的文字复制到文件中
1 2 3 4 5 6 7 8 9 10 11 12 const http = require ("http" );const requestListener = function (req, res ) { res.writeHead (200 ); res.end ("Hello, World!" ); }; const server = http.createServer (requestListener);server.listen (8080 );
写好后保存,再当前文件夹下打开终端,输入node 文件名.js,即可开启一个服务。
服务端改了东西,想要生效 的话,需要重启服务 ,Ctrl + C 。结束任务后,再 node 文件名开启服务就可以了。
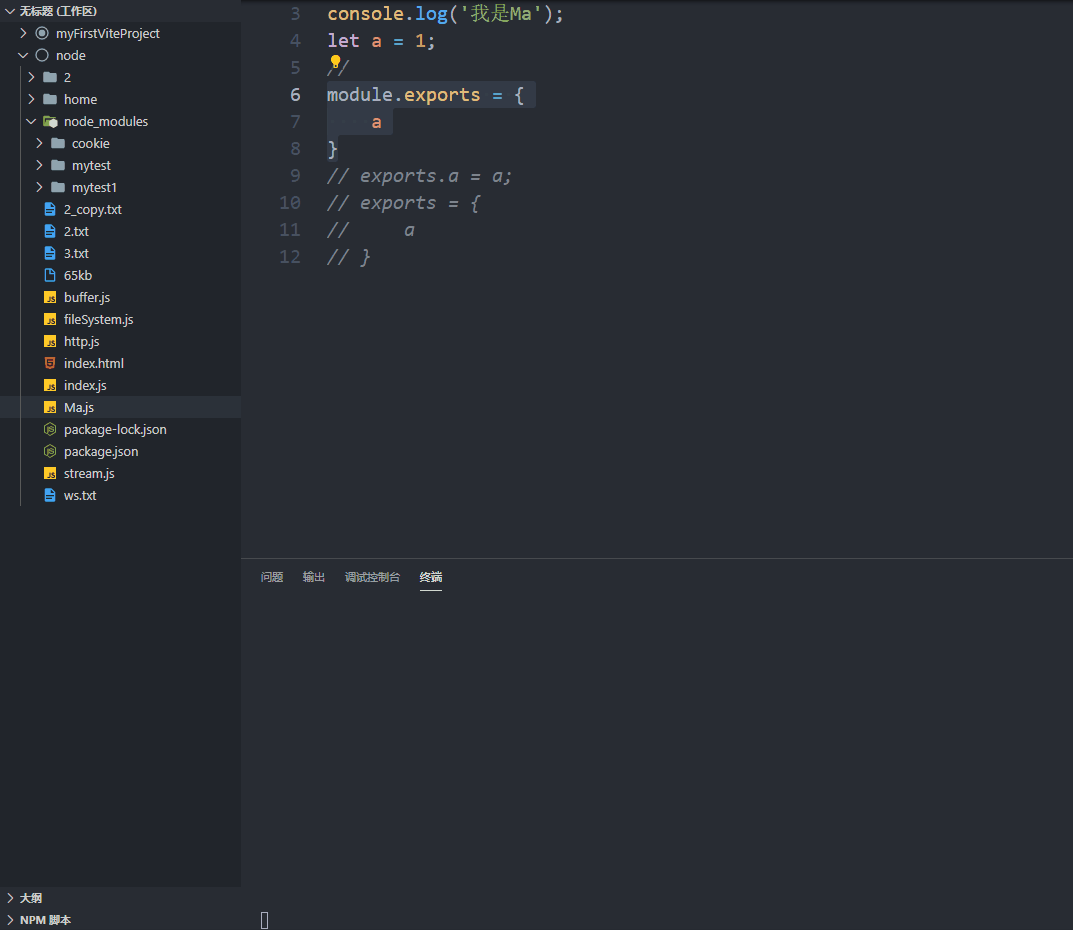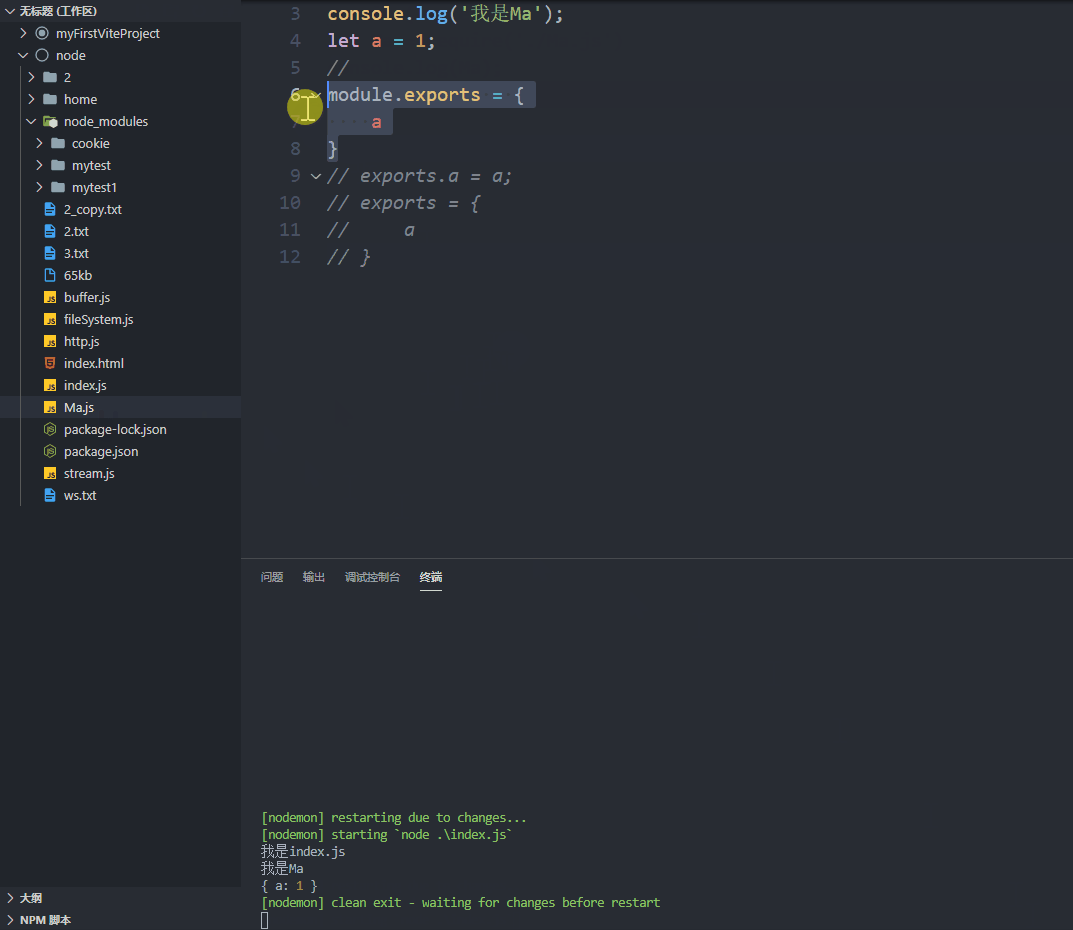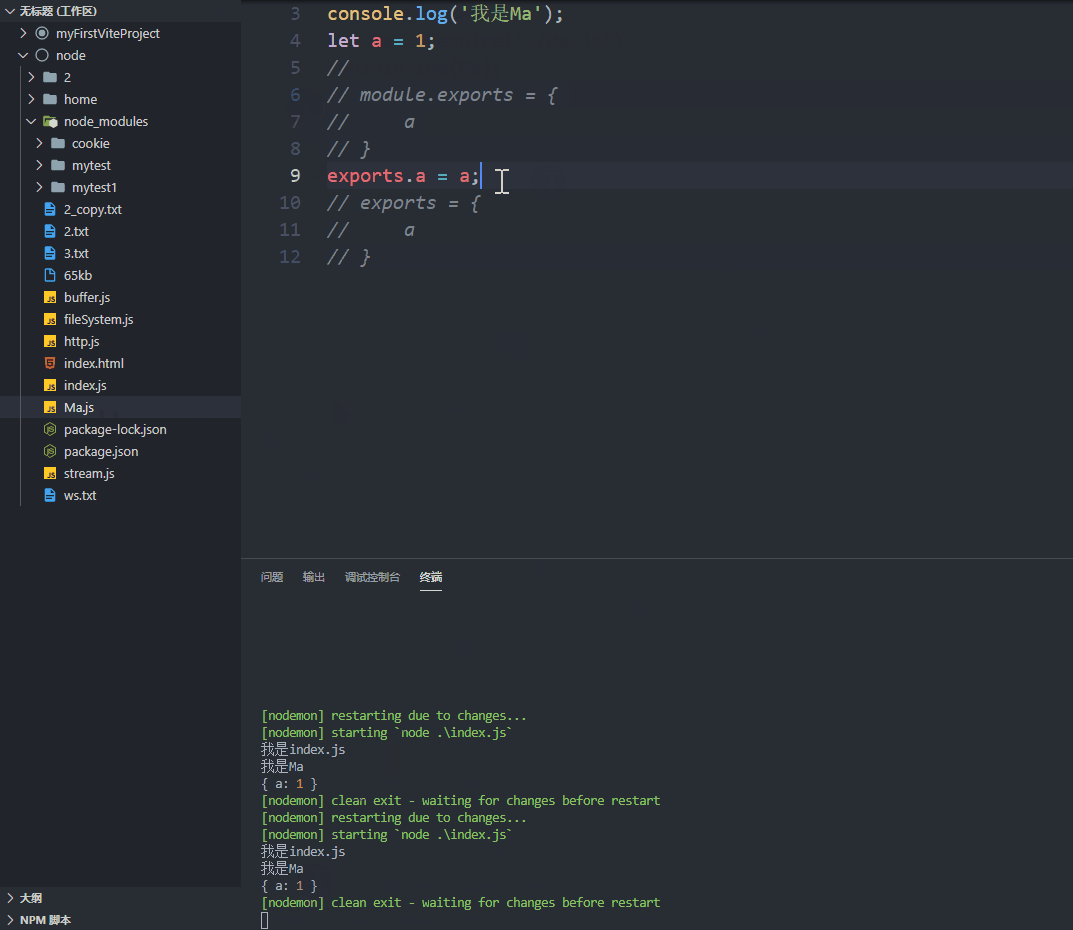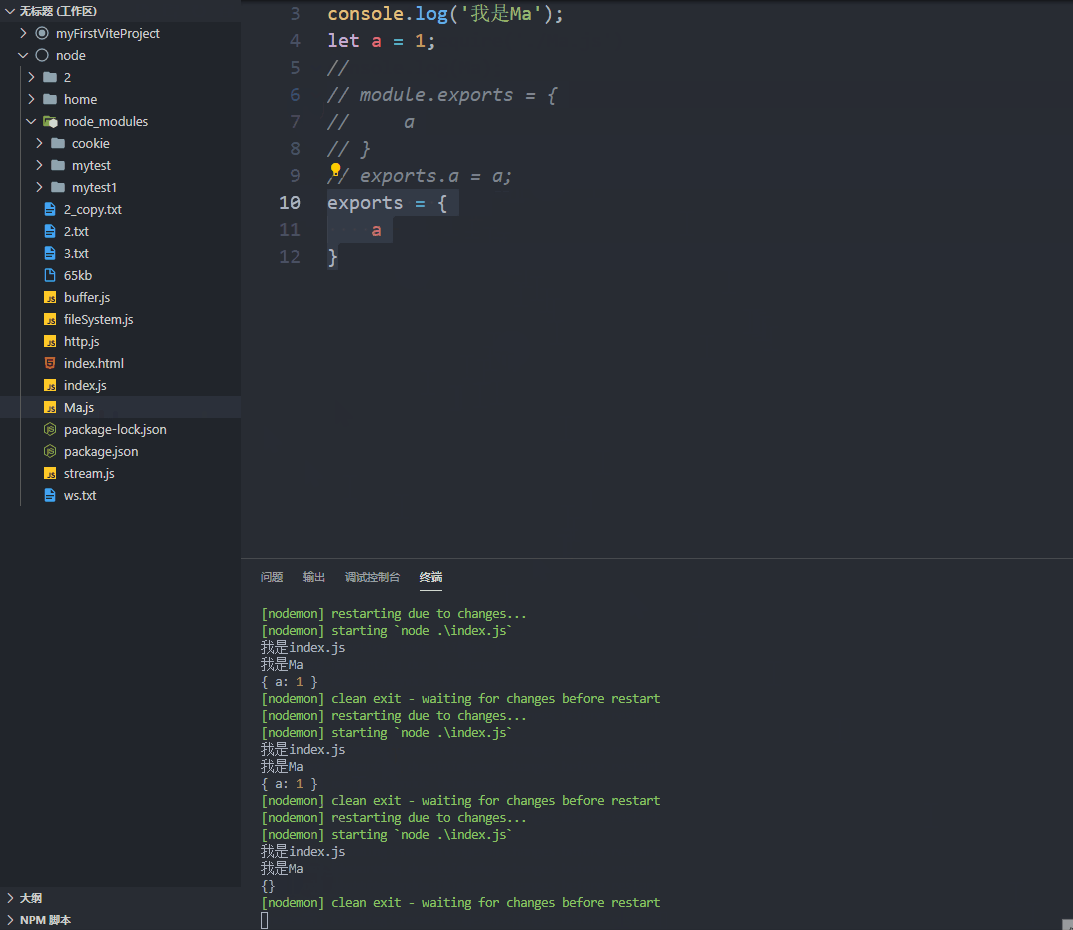
nodemon nodemon 避免重启服务,nodemon 有热更新的功能,就是修改文件后可以帮你重新起服务npm install nodemon - g,-g代表安装到全局,后面会详细记录 npm 的常用命令nodemon 文件名.js (跟 node 启动服务类似的)
模块化
问题:随着项目的不断扩大,变量名也会越来越多,那么总会有可能有些变量命名重复了,那么我们有什么好的办法去解决这个问题?commonJS 规范,概括的思想就是,一个文件就是一个作用域。
模块中的变量导出
模块化的优点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 module .exports = { a, }; exports .a = a;exports = { a, };
想了解更多 exports 和 module.exports 的区别可以看这里。
模块中的变量引入 如果模块是在node_modules 下的文件夹,那么可以直接引入
如果不在node_modules 下的文件夹,那么,文件引入时写路径的 ./ 是不能省略的,但是文件后缀名可以省略。比方 require("./Mb");
整合引入 我们可以写一个入口文件,专门存放一些引入的,比方说下图中的 index.js
历史上的模块化的集中形式(了解) amd sea.js 略…
cmd require.js 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 <!DOCTYPE html > <html lang ="en" > <head > <meta charset ="UTF-8" /> <meta http-equiv ="X-UA-Compatible" content ="IE=edge" /> <meta name ="viewport" content ="width=device-width, initial-scale=1.0" /> <title > Document</title > <script src ="https://cdn.bootcss.com/require.js/2.3.6/require.js" > </script > </head > <body > </body > <script > require (["a" ], (obj ) => { console .log ("我是 a.js 中的 obj :>>" , obj); console .log (a); }); </script > </html > // 打印如下 a.js:2 我是a.js b.js:2 我是b.js a.js:4 我是 b.js 中的变量:>> {str: "我是b.js的变量"} index.html:16 我是 a.js 中的 obj :>> {name: "蔡徐坤"} index.html:17 1
1 2 3 4 5 6 7 8 9 let a = 1 ; console .log ("我是a.js" );define (["b.js" ], function (obj ) { console .log ("我是 b.js 中的变量:>>" , obj); return { name : "蔡徐坤" , }; });
1 2 3 4 5 6 7 define (function ( console .log ("我是b.js" ); let str = "我是b.js的变量" ; return { str, }; });
以上就是些有用的基本知识啦,接下来是一些常用内置模块的介绍
Node 常用内置模块 大体有如下模块,乌泱泱一堆啊。
Buffer,C/C++Addons,Child Processes,Cluster,Console,Crypto,Debugger,DNS,Domain,Errors,Events,File System,Globals,HTTP,HTTPS,Modules,Net,OS,Path,Process,Punycode,Query Strings,Readline,REPL,Stream,String De coder,Timers,TLS/SSL,TTY,UDP/Datagram,URL, Utilities,V8,VM,ZLIB;
内置模块不需要安装,外置模块需要安装;
fs 文件操作 * 文件操作分为两个大类
文件操作
目录操作
顾名思义,操作的目标不同而已
所有的操作都分同步和异步的,区别就是是否加 Sync
文件操作 写入文件 1 2 3 4 5 6 7 8 9 10 11 12 13 fs.writeFile ("1.txt" , "我是写入的文字" , { flag : "a" }, function (err ) { if (err) { console .log (err); } console .log ("写入成功" ); });
读取文件 1 2 3 4 5 6 7 8 9 10 11 fs.readFile ("1.txt" , "utf8" , (err, data ) => { if (err) { console .log (err); } console .log (data); });
如果这些操作没有添加Sync,都是异步的。
如何修改成同步的呢?只需添加上Sync即可,同步的话就没有回调函数了 ,下面就是例子
1 2 let rst = fs.readFileSync ("1.txt" );console .log (rst.toString ());
修改文件名 1 2 3 4 5 6 7 fs.rename ("1.txt" , "2.txt" , (err ) => { if (err) { return console .log (err); } console .log ("修改成功" ); });
删除文件 1 2 3 4 5 6 fs.unlink ("2.txt" , (err ) => { if (err) { return console .log (err); } console .log ("删除成功" ); });
复制文件 复制文件有两个办法
先读文件,再写文件
使用 copyFile
1 2 3 4 5 6 7 8 9 10 11 12 13 const myCopy = (src, dest ) => { fs.writeFileSync (dest, fs.readFileSync (src)); }; myCopy ("2.txt" , "3.txt" );fs.copyFile ("2.txt" , "2_copy.txt" , (err ) => { if (err) { return console .log (err); } console .log ("复制成功" ); });
目录操作 创建目录 1 2 3 4 5 6 7 8 9 fs.mkdir ("1" , (err ) => { if (err) { return console .log (err); } console .log ("创建成功" ); });
修改目录名 1 2 3 4 5 6 7 8 9 fs.rename ("1" , "2" , (err ) => { if (err) { return console .log (err); } console .log ("修改文件夹名称成功" ); });
读取目录 默认只读一层目录,什么意思呢,就是你读取的目录下也可能有文件夹是吧?那么这个文件夹中的内容就不会读了。
1 2 3 4 5 6 7 8 9 fs.readdir ("2" , (err, data ) => { if (err) { return console .log ("err" ); } console .log ("读取目录:>>" , data); });
删除空文件夹 1 2 3 4 5 6 7 8 9 10 fs.rmdir ("2" , (err ) => { if (err) { return console .log (err); } console .log ("删除成功:>>" , data); });
删除非空文件夹 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 function removeDir (path ) { let data = fs.readdirSync (path); for (let i = 0 ; i < data.length ; i++) { let url = path + "/" + data[i]; let stat = fs.statSync (url); if (stat.isDirectory ()) { removeDir (url); } else { fs.unlinkSync (url); } } fs.rmdirSync (path); } removeDir ("2 copy" );
我写的版本 刚开始我没看他写的,自己想了想,我自己写的一个版本,差了一点。
第一版:比较可惜,就差一点点没写出来,就是最后删文件夹那一步
我还在想如何去删空的文件夹,其实当我们把当前文件夹下的文件都删除掉了,就可以直接删除空文件夹了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 function df (dirName ) { let dirArr = fs.readdirSync (dirName); dirArr.forEach ((item ) => { console .log (item); const path = `${dirName} /${item} ` ; fs.stat (path, (err, stat ) => { console .log (path); if (err) { return err; } if (stat.isDirectory () === true ) { df (path); } if (stat.isFile () === true ) { fs.unlinkSync (path); } }); }); }
第二版:fs.stat 不能写成异步的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 function df (dirName ) { let dirArr = fs.readdirSync (dirName); dirArr.forEach ((item ) => { const path = `${dirName} /${item} ` ; fs.stat (path, (err, stat ) => { if (stat.isDirectory () === true ) { df (path); } else { fs.unlinkSync (path); } }); }); fs.rmdirSync (dirName); }
最终版
1 2 3 4 5 6 7 8 9 10 11 12 13 function df (dirName ) { let dirArr = fs.readdirSync (dirName); dirArr.forEach ((item ) => { const path = `${dirName} /${item} ` ; let stat = fs.statSync (path); if (stat.isDirectory () === true ) { df (path); } else { fs.unlinkSync (path); } }); fs.rmdirSync (dirName); }
通用方法 判断文件或者文件夹是否存在 1 2 3 fs.exists ("a.txt" , (isexists ) => { console .log (isexists); });
获取文件或者目录的详细信息 / 判断文件、目录 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 fs.stat ("index.html" , (err, stat ) => { if (err) { return console .log (err); } let isFile = stat.isFile (); console .log (isFile); let isDirectory = stat.isDirectory (); console .log (isDirectory); stat.isFile (); });
速查表格
功能
函数
文件操作
写入文件
fs.writeFile
读取文件
fs.readFile
修改文件名
fs.rename
删除文件
fs.unlink
复制文件
fs.copyFile
目录操作
创建目录
fs.mkdir
修改目录名fs.rename
读取目录
fs.readdir(path)
删除空 文件夹
fs.rmdir
通用方法
判断文件或者文件夹是否存在fs.exists
获取文件或者目录的详细信息
fs.stat
判断文件
stat.isFile()
判断是否是目录
stat.isDirectory()
buffer 模块 概念 在文件读取的时候,如果不声明 utf8 的时候,我们打印出来的是 buffer ,那么什么是 buffer 呢?
可以理解成为一个数据格式
为啥要用buffer?
创建 buffer 指定创建 10 字节的 buffer
1 2 3 4 let buffer = Buffer .alloc (10 ); console .log (buffer);
创建内容为文字的 buffer 流
1 2 let buffer1 = Buffer .from ("大家好" );console .log (buffer1);
可以观察并推测到一个文字对应三个 buffer 字节
我们还可以通过数组的形式来创建
1 2 3 4 5 let buffer2 = Buffer .from ([ 0xe5 , 0xa4 , 0xa7 , 0xe5 , 0xae , 0xb6 , 0xe5 , 0xa5 , 0xbd , ]); console .log (buffer2); console .log (buffer2.toString ());
转换成字符串 toString
拼接二进制流可以用concat方法
1 2 3 4 5 6 let buffer3 = Buffer .from ([0xe5 , 0xa4 , 0xa7 , 0xe5 ]);let buffer4 = Buffer .from ([0xae , 0xb6 , 0xe5 , 0xa5 , 0xbd ]);console .log (buffer3.toString ()); let newbuffer = Buffer .concat ([buffer3, buffer4]);console .log (newbuffer.toString ());
从以上的例子我们可以推断出,一个汉字占用 3 个字节,可以看到大后面的乱码,就是因为没有字节去描述这个汉字了,所以就乱码了…
或者可以通过node给的方法 StringDecoder ,此方法会把第一个多余的buffer存起来,然后跟第二个拼接起来,所以不会出现乱码。
1 2 3 4 5 6 7 8 let { StringDecoder } = require ("string_decoder" );let decoder = new StringDecoder ();let buffer3 = Buffer .from ([0xe5 , 0xa4 , 0xa7 , 0xe5 ]);let buffer4 = Buffer .from ([0xae , 0xb6 , 0xe5 , 0xa5 , 0xbd ]);let res3 = decoder.write (buffer3);let res4 = decoder.write (buffer4);console .log (res3); console .log (res4);
stream 流 为啥要用流?
为啥要用流呢?
也就是把大象装冰箱里,总共分几步的问题~
首先创建二进制流并写入文件
1 2 3 4 5 6 7 8 9 10 let buffer = Buffer .alloc (65 * 1024 );fs.writeFile ("65kb" , buffer, (err ) => { if (err) { return console .log (err); } console .log ("写入成功!" ); });
然后创建流读取 fs.createReadStream()
1 2 3 4 5 6 7 const fs = require ("fs" );let num = 0 ;let rs = fs.createReadStream ("65kb" ); rs.on ("data" , (chunk ) => { ++num; console .log (chunk, num); });
输出结果如下:
chunk 能有多大(验证)? 那么流会每次会把文件分成多大份呢?我们来做一个实验
我们在上面的操作图片中能够看到,65kb 大小的文件,是分成两个流的
所以我们推断,分流每次切成64字节的chunk
如何判断流完成? 可以通过 on 中的end 来判断
1 2 3 4 5 6 7 8 9 10 11 const fs = require ("fs" );let num = 0 ;let rs = fs.createReadStream ("65kb" ); rs.on ("data" , (chunk ) => { ++num; console .log (chunk, num); }); rs.on ("end" , () => { console .log ("流完成" ); });
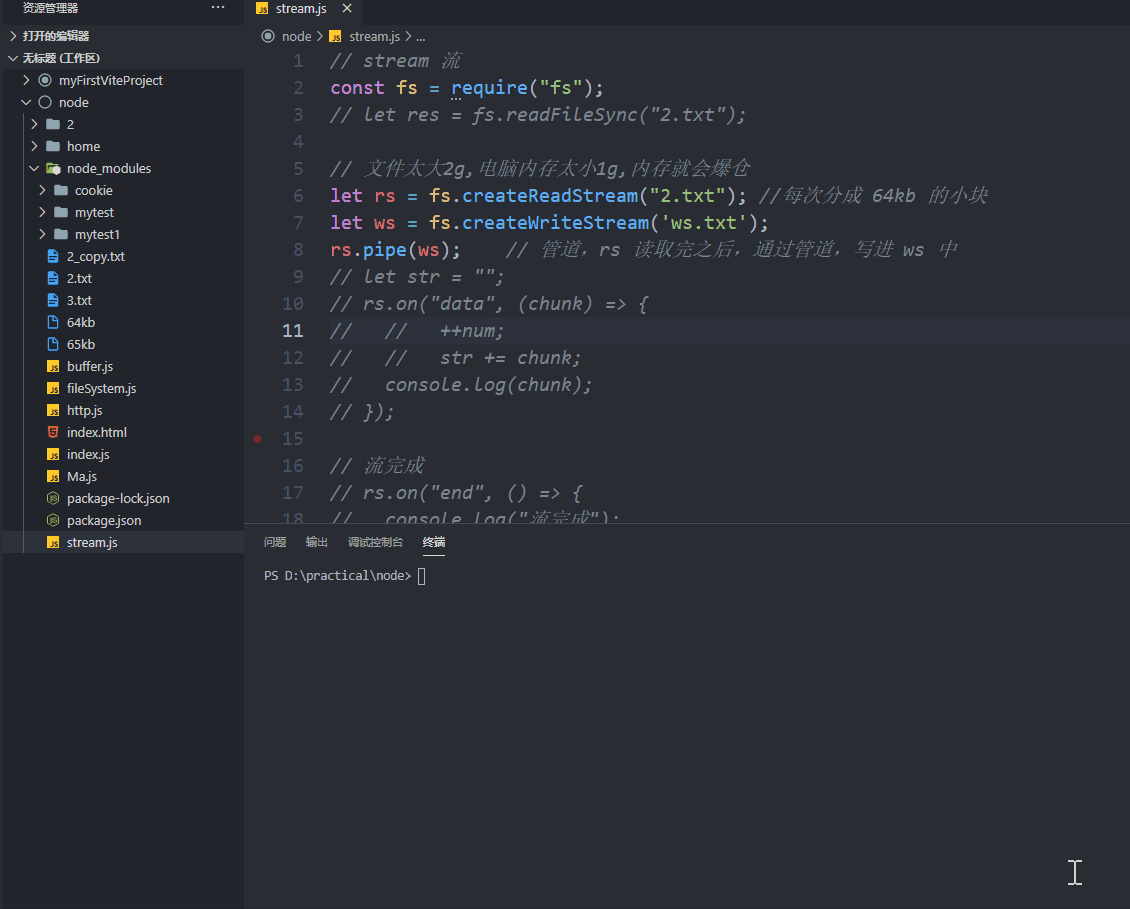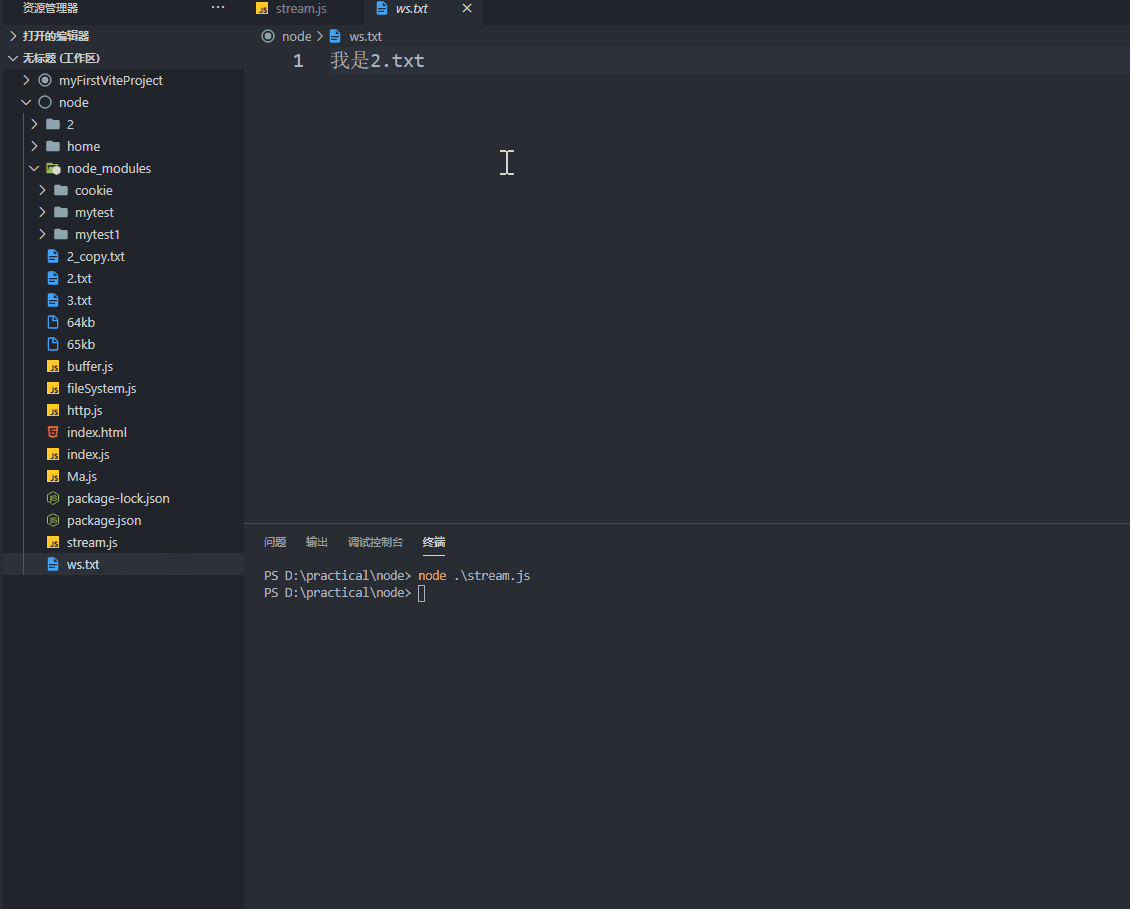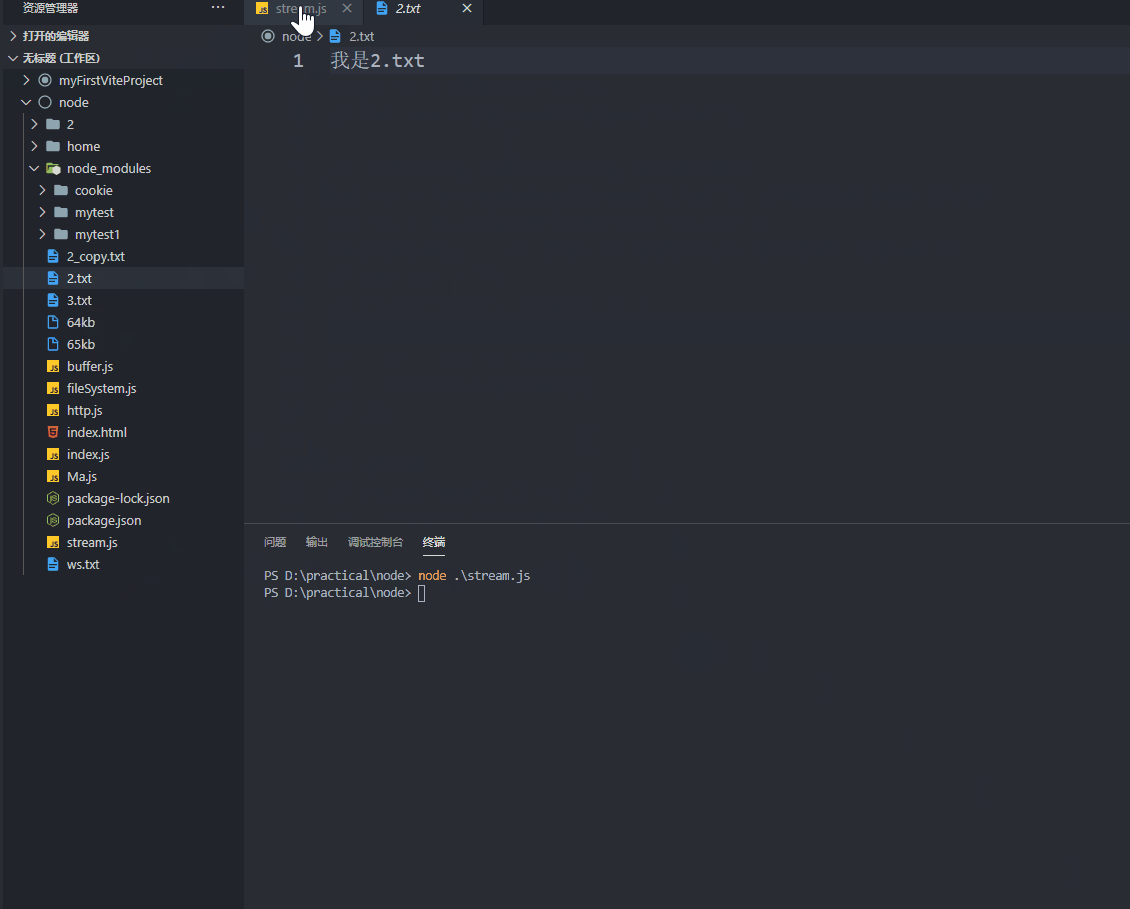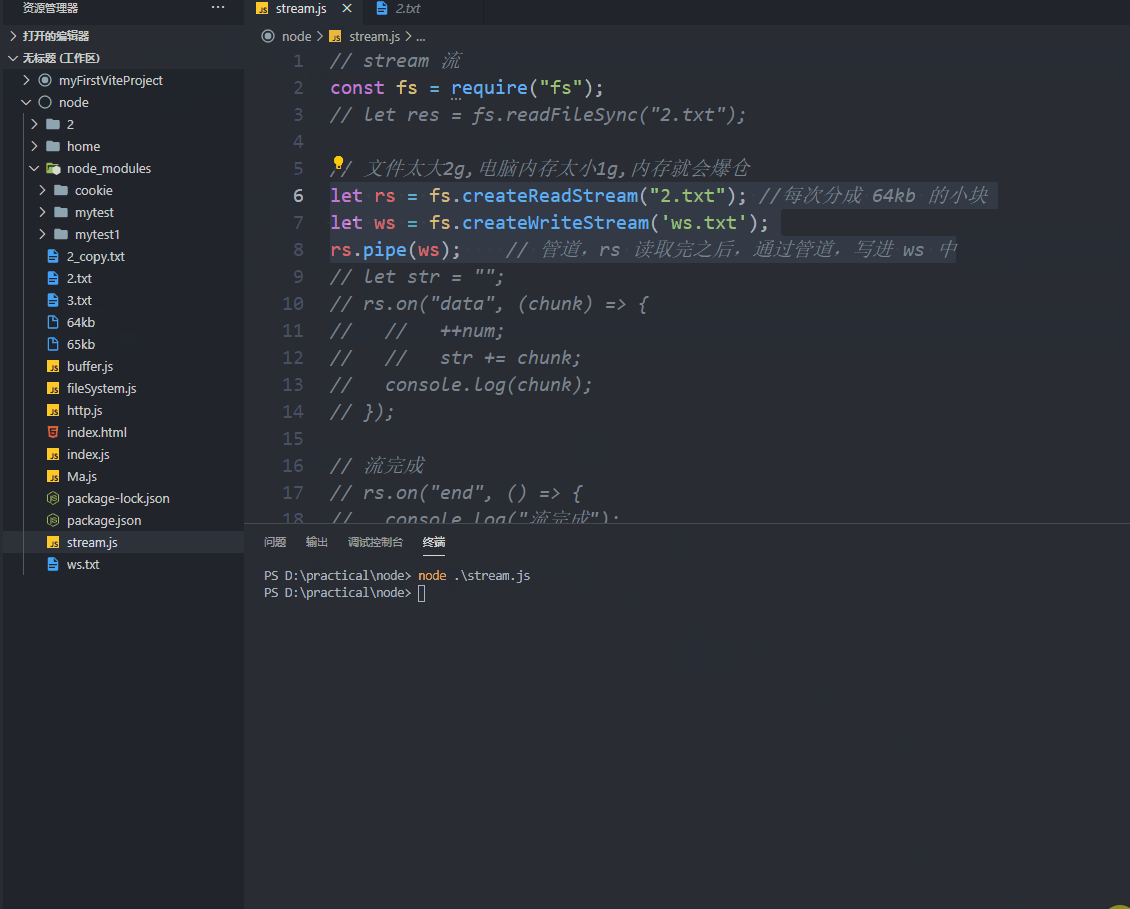
管道 pipe pipe 译为管道,我们呢创建好读取流之后,通过管道,我们把chunk 写入某文件中并拼接,跟赋值的操作差不多啊,这样的操作如下~
1 2 3 4 const fs = require ("fs" );let rs = fs.createReadStream ("65kb" ); let ws = fs.createWriteStream ("ws.txt" ); rs.pipe (ws);